近日,福州大学数字中国研究院(福建)博士研究生郑强文(指导教师吴升教授)在顶级期刊Information Processing & Management(SCI/SSCI,中科院一区TOP,影响因子:7.4)发表交通三维目标检测研究成果——VoxT-GNN: A 3D Object Detection Approach from Point Cloud based on Voxel-Level Transformer and Graph Neural Network。

现有基于LiDAR点云的自动驾驶3D目标检测方法面临多尺度感知的核心挑战:静态感受野设计较难有效适配道路场景中汽车、行人、骑行者等异构目标的显著尺度差异,而传统跨尺度特征融合机制在复杂空间分布下易引发层级间特征干扰,导致细粒度几何信息与语义表征的耦合效能降低。为解决上述问题,本研究提出了一种顾及尺度差异的3D目标检测框架VoxT-GNN,将点云处理建模为集合到集合的变换,通过设计均衡化局部感受野和可变全局感受野的局部-全局特征协同学习机制有效提升复杂场景下的3D检测性能。VoxT-GNN主要包括VoxelFormer(Voxel-Level Transformer)和GnnFFN(GNN Feed-Forward Network) 两个核心组件。前者在体素区域内建立局部几何关系,通过约简的交叉注意力机制提取细粒度的局部特征;后者则在非空体素之间构建全局上下文关联,使用点卷积图神经网络实现跨体素(跨尺度)特征交互。特别地,通过将GnnFFN嵌入VoxelFormer编码器-解码器架构的中间层,系统实现了局部细节与全局语义的渐进式融合。这种层次化设计在尽可能保持点云原始几何结构的前提下,通过均衡化局部和可变全局感受野,有效缓解了小目标特征易受干扰的问题。为验证方法的泛化性与鲁棒性,本研究在KITTI与Waymo Open Dataset自动驾驶基准上开展了实验验证。实验结果表明,在单阶段与两阶段检测框架中,与当前最先进的基线方法相比,VoxT-GNN在检测性能上表现出了较强竞争力,尤其是在小目标检测中更加显著,并且在KITTI中的汽车、行人和骑行者三个类别上的综合性能达到SOTA级水平(纯点云驱动的方法)。
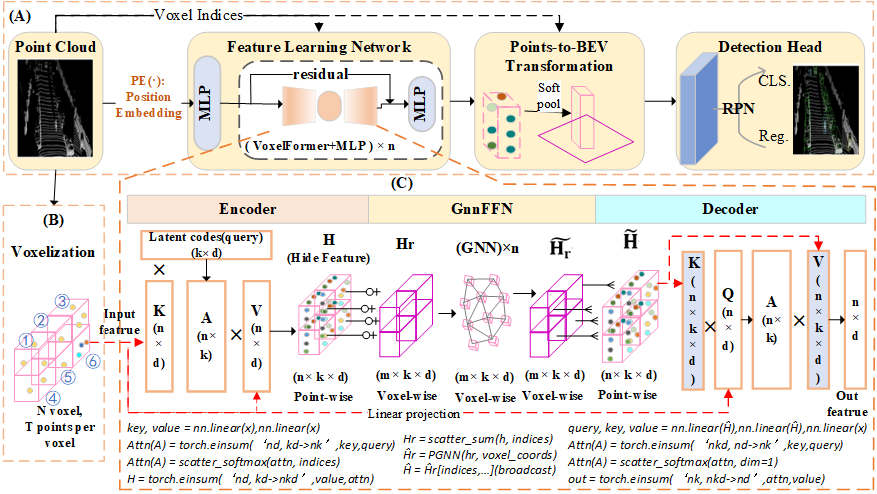
图1 VoxT-GNN总体框架
论文引用:
Zheng, Q., S. Wu and J. Wei, VoxT-GNN: A 3D object detection approach from point cloud based on voxel-level transformer and graph neural network. Information Processing & Management, 2025. 62(4): p. 104155.https://doi.org/10.1016/j.ipm.2025.104155
论文链接:https://www.sciencedirect.com/science/article/pii/S0306457325000962
